|
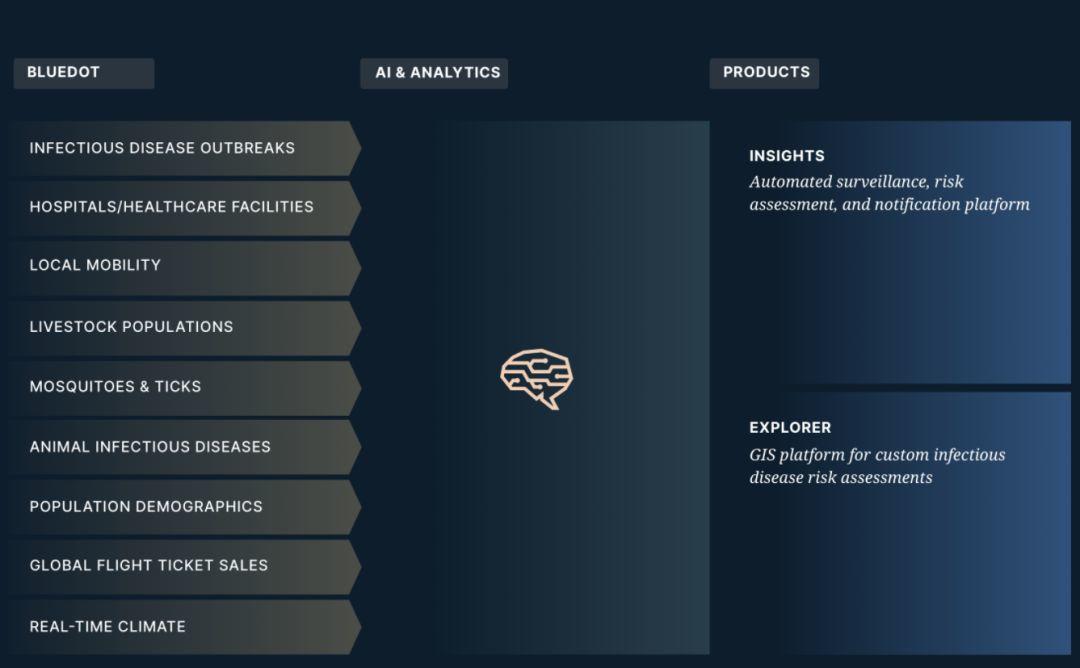
一直以来,尽管外界一直希望谷歌能够公开GFT的算法,谷歌并没有选择公开。这让很多研究人员质疑这些数据是否可以重复再现或者存在更多商业上的考虑。他们希望应该将搜索大数据和传统的数据统计(小数据)结合起来,创建对人类行为更深入、准确的研究。 显然,谷歌并没有重视这一意见。最终在2015年GFT正式下线。但其仍在继续收集相关用户的搜索数据,仅提供给美国疾控中心以及一些研究机构使用。 二、为什么BlueDot率先成功预测:AI算法与人工分析的协奏曲众所周知,谷歌在当时已经在布局人工智能,2014年收购DeepMind,但依然保持它的独立运营。同时,谷歌也没有GFT再投入更多关注,因此也并未考虑将AI加入到GFT的算法模型当中,而是选择了让GFT走向“安乐死”。几乎在同一时期,今天我们所见到的BlueDot诞生。 BlueDot是由传染病专家卡姆兰·克汗(Kamran Khan)建立流行病自动监测系统,通过每天分析65种语言的约10万篇文章,来跟踪100多种传染病爆发情况。他们试图用这些定向数据收集来获知潜在流行传染病爆发和扩散的线索。 BlueDot一直使用自然语言处理(NLP)和机器学习(ML)来训练该“疾病自动监测平台”,这样不仅可以识别和排除数据中的无关“噪音”。 比如,系统识别这是蒙古炭疽病的爆发,还仅仅是1981年成立的重金属乐队“炭疽”的重聚。 又比如GFT仅仅将“流感”相关搜索的用户理解为可能的流感病患者,显然出现过多不相关用户而造成流行病准确率的高估。 这也是BlueDot区别于GFT在对关键数据进行甄别的优势之处。 就像在这次在新型冠状病毒疫情的预测中,卡姆兰表示,BlueDot通过搜索外语新闻报道,动植物疾病网络和官方公告来找到疫情信息源头。但该平台算法不使用社交媒体的发布内容,因为这些数据太过杂乱容易出现更多“噪音”。 关于病毒爆发后的传播路径预测,BlueDot更倾向于使用访问全球机票数据,从而更好发现被感染的居民的动向和行动时间。在1月初的时候,BlueDot也成功预测了新型冠状病毒从武汉爆发后,几天之内从武汉扩散至北京、曼谷、汉城及台北。新冠病毒爆发并非是BlueDot的第一次成功: 在2016年,通过对巴西寨卡病毒的传播路径建立AI模型的分析,BlueDot成功地提前六个月预测在美国佛罗里达州出现寨卡病毒。 这意味着BlueDot的AI监测能力甚至可以做到预测流行病的地域蔓延轨迹。 从失败到成功,BlueDot和谷歌GFT之间究竟存有哪些差异? 1. 预测技术差异之前主流的预测分析方法采取的是数据挖掘的一系列技术,其中经常用到的数理统计中的“回归”方法,包括多元线性回归、多项式回归、多因Logistic回归等方法,其本质是一种曲线的拟合,就是不同模型的“条件均值”预测。这也正是GFT所采用的预测算法的技术原理。 在机器学习之前,多元回归分析提供了一种处理多样条件的有效方法,可以尝试找到一个预测数据失误最小化且“拟合优度”最大化的结果。但回归分析对于历史数据的无偏差预测的渴求,并不能保证未来预测数据的准确度,这就会造成所谓的“过度拟合”。 据北大国研院教授沈艳在《大数据分析的光荣与陷阱——从谷歌流感趋势谈起》一文中分析,谷歌GFT确实存在“过度拟合”的问题。 也就是在2009年GFT可以观察到2007-2008年间的全部CDC数据,采用的训练数据和检验数据寻找最佳模型的方法所参照的标准就是——不惜代价高度拟合CDC数据。 所以,在2014年的《Science》论文中指出,会出现GFT在预测2007-2008年流感流行率时,存在丢掉一些看似古怪的搜索词,而用另外的5000万搜索词去拟合1152个数据点的情况。 2009年之后,GFT要预测的数据就将面临更多未知变量的存在,包括它自身的预测也参与到了这个数据反馈当中。无论GFT如何调整,它仍然要面对过度拟合问题,使得系统整体误差无法避免。 BlueDot采取了另外一项策略,即医疗、卫生专业知识和人工智能、大数据分析技术结合的方式,去跟踪并预测流行传染病在全球分布、蔓延的趋势,并给出最佳解决方案。
BlueDot主要采用自然语言处理和机器学习来提升该监测引擎的效用。随着近几年算力的提升以及机器学习,从根本上彻底改变了统计学预测的方法。 主要是深度学习(神经网络)的应用,采用了“反向传播”的方法,可以从数据中不断训练、反馈、学习,获取“知识”,经过系统的自我学习,预测模型会得到不断优化,预测准确性也在随着学习而改进。 而模型训练前的历史数据输入则变得尤为关键。足够丰富的带特征数据是预测模型得以训练的基础。经过清洗的优质数据和提取恰当标注的特征成为预测能否成功的重中之重。 2. 预测模式差异与GFT完全将预测过程交给大数据算法的结果的方式不同,BlueDot并没有完全把预测交给AI监测系统。BlueDot是在数据筛选完毕后,会交给人工分析。这也正是GFT的大数据分析的“相关性”思维与BlueDot的“专家经验型”预测模式的不同。 所分析的大数据是选取特定网站(医疗卫生、健康疾病新闻类)和平台(航空机票等)的信息。而AI所给出的预警信息也需要相关流行病学家的再次分析才能进行确认是否正常,从而评估这些疫情信息能否第一时间向社会公布。 当然,就目前这些案例还不能说明BlueDot在预测流行病方面已经完全取得成功: 首先,AI训练模型是否也会存在一些偏见,比如为避免漏报,是否会过分夸大流行病的严重程度,因而再次出现“狼来了”的问题?其次,监测模型所评估的数据是否有效,比如BlueDot谨慎使用社交媒体的数据来避免过多的“噪音”? 幸而BlueDot作为一家专业的健康服务平台,他们会比GFT更关注监测结果的准确性。 毕竟,专业的流行病专家是这些预测报告的最终发布人,其预测的准确度直接会影响其平台信誉和商业价值。 这也意味着,BlueDot还需要面临如何平衡商业化盈利与公共责任、信息开放等方面的一些考验。 三、AI预测流行病爆发,仅仅是序曲……《发出第一条武汉冠状病毒警告的是人工智能?》媒体的这一标题确实让很多人惊讶。 在全球一体化的当下,任何一地流行疾病的爆发都有可能短时间内传遍全球任何一个角落,发现时间和预警通报效率就成为预防流行疾病的关键。 如果AI能够成为更好的流行病预警机制,那不失为世界卫生组织(WHO)以及各国的卫生健康部门进行流行病预防机制的一个办法。那这又要涉及到这些机构组织如何采信AI提供的流行病预报结果的问题。 未来,流行病AI预测平台还必须提供流行病传染风险等级,以及疾病传播可能造成的经济、政治风险的等级的评估,来帮助相关部门做出更稳妥的决策。 而这一切,仍然需要时间。这些组织机构在建立快速反应的流行病预防机制中,也应当把这一AI监测系统提上日程了。 可以说,此次AI对流行病爆发提前成功地预测,是人类应对这场全球疫情危机的一抹亮色。 希望这场人工智能参与的疫情防控的战役只是这场持久战的序曲,未来应该有更多可能。 比如,主要传染病病原体的AI识别应用;基于主要传染病疫区和传染病的季节性流行数据建立传染病AI预警机制;AI协助传染病爆发后的医疗物资的优化调配等。 这些让我们拭目以待。
作者:脑极体,微信公众号:脑极体 本文由 @脑极体 原创发布于人人都是产品经理。未经许可,禁止转载。 题图来自Unsplash, 基于CC0协议 (责任编辑:admin) |
| Tags: see you again歌词 江南 歌词 永丰党建网 休息日 漂亮女人 屋塔房 英强 |


栏目分类
创业新闻相关信息
热门创业新闻文章推荐

“全国新闻媒体采风行” 走进
烟雨江南品味风雅常熟 七溪流水皆
50、60、70、80、90五个年代创
昨日,众多国内知名创投大咖与内外-
返乡创业 打造生态观光农业园
媒体参观生态放养的巴马香猪 核桃 -
教你如何用签到功能让你的用户
在如今这个缺信仰、缺钱、缺爱,唯 -
盐阜网元旦献词:继续做好新闻
盐阜网讯:今日元旦,新年起航。值 -
我想创业怎么创业,德升互联第
我想创业怎么创业,德升互联第一时 -
创业最痛苦的事莫过于:一个好
进群方法:关注创友社群微信公众号 -
“小红叔”创业心得:独立思考
长江后浪推前浪,当今世界仍然需要 -
舟山玩具厂厂长的创业守业心路
定海新闻网是定海区继报纸、广播、 -
低效等死!互联网+时代创业如
在大众创业,万众创新时代,创业公
广告赞助商
创业新闻文章阅读排
- 创业融资防骗指南:对赌协议/股权稀释/虚假估
- 社区团购还能做吗?资深玩家分享私域流量运营
- 宝妈专属:五大时间灵活的居家创业项目精选
- 上班族副业转型指南:TOP10轻资产项目深度解
- 从全职妈妈到收纳大师:柔性技能如何引领万亿
- 揭秘伪需求:商业模式如何应对真实痛点挑战
- 汉韵新生:95后夫妻档如何将汉服租赁打造成传
- 绿色经济浪潮下:环保科技领域的潜力小众蓝海
- 奶茶店创业避坑指南:从0到1开店全攻略
- 融合创新:残疾程序员打造无障碍软件,实现社
- 家政保洁维修行业:五大高效获客策略解析
- AI浪潮下的创业新机遇:普通人如何乘风破浪,
- 202X年热门低门槛创业项目大盘点:抓住机遇,
- 法律底线不容逾越:知识产权、劳动合规与税务
- 临期食品逆袭记:折扣超市与社群团购的共赢策
- 从全职妈妈到收纳大师:柔性技能如何引领万亿
- 补贴依赖企业的风险与政策变动应对策略解析
- 跨境电商新手攻略:选品智慧、物流攻略与平台
- 两年风雨创业 我把18000元改写为90万
- 小镇奇迹:手工皂女王年销千万的创业传奇
◎ 主页 > 创业新闻 > INTRODUCE
AI 预测武汉疫情,创业公司如何攻占AI流行病预测?(2)
see you again歌词
江南 歌词
永丰党建网
休息日
漂亮女人
屋塔房
英强
顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
特别说明
此处放横条广告
◎ 阅读说明READ EXPLANATION
☉推荐使用第三方专业下载工具下载本站软件,使用 WinRAR v3.10 以上版本解压本站软件。
☉如果这个软件总是不能下载的请点击报告错误,谢谢合作!!
☉下载本站资源,如果服务器暂不能下载请过一段时间重试!
☉如果遇到什么问题,请到本站论坛去咨寻,我们将在那里提供更多 、更好的资源!
☉本站提供的一些商业软件是供学习研究之用,如用于商业用途,请购买正版。
谈谈您对该文章的看